Choria Registration Data
We’ll show a full end to end walkthrough of building a centralized node metadata store for all your fleet nodes in multiple locations, including advisories about their availability.
While the central store will get data for any single node hourly it will also get advisories letting it know when a node has not been seen for 11 minutes and when a node has not been seen for a hour allowing an up to date node view to be maintained. The in-datacenter data stores will have data no older than 5 minutes.
Data processing can be done in-datacenter and centrally using any of the 40+ languages NATS supports. One can even add a middle aggregation tier or complex tree like structures. Data cen be replicated once as here or multiple times to multiple locations and teams with different sampling strategies.
To achieve this we will use Choria Data Adapters to place data into Choria Streams and the replicator to move it to a central JetStream Cluster.
This is typically something you would do along with a Large Scale Choria Deployment spanning many locations and potentially millions of nodes.
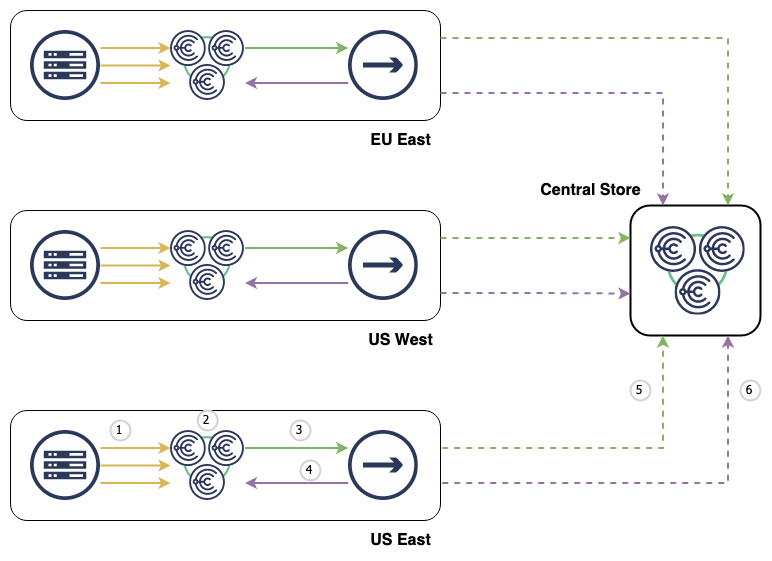
Above diagram demonstrates what we will construct:
- Choria Fleet Nodes publish their metadata every 300 seconds
- Choria Data Adapters place the data in the
CHORIA_REGISTRATIONstream with per-sender identifying information - Stream Replicator reads all messages in the
CHORIA_REGISTRATIONStream - Sampling is applied and advisories are sent to the
CHORIA_REGISTRATION_ADVISORIESstream about node movements and health - Sampled Fleet Node metadata is replicated to central into the
CHORIA_REGISTRATIONstream - All advisories are replicated to central into the
CHORIA_REGISTRATION_ADVISORIESstream
While not shown here these methods can be combined with the techniques in HA Clustering
Choria Streams Broker
First we need to enable Choria Streams - an embedded, managed, version of NATS JetStream.
# /etc/choria/broker.conf
plugin.choria.network.stream.store = /var/lib/choria
This stores our data in /var/lib/choria and sets up some basic streams. If the server is clustered it will form a RAFT-replicated Streams cluster.
Choria Streams Data Adapter
We now need to create a stream that will hold our in-datacenter data, we keep 5 most recent data items for any node and store any nodes data for no longer than a day.
$ choria broker stream add CHORIA_REGISTRATION
? Subjects to consume choria.stream.input.registration.>
? Storage backend file
? Retention Policy Limits
? Discard Policy Old
? Stream Messages Limit -1
? Per Subject Messages Limit 5
? Stream size limit -1
? Maximum message age limit 1d
? Maximum individual message size -1
? Duplicate tracking time window 2m0s
? Allow message Roll-ups No
? Allow message deletion Yes
? Allow purging subjects or the entire stream Yes
? Replicas 1
Stream CHORIA_REGISTRATION was created
Information for Stream CHORIA_REGISTRATION created 2022-03-15T17:20:24+01:00
Configuration:
Subjects: choria.stream.input.registration.>
Acknowledgements: true
Retention: File - Limits
Replicas: 1
Discard Policy: Old
Duplicate Window: 2m0s
Allows Msg Delete: true
Allows Purge: true
Allows Rollups: false
Maximum Messages: unlimited
Maximum Per Subject: 5
Maximum Bytes: unlimited
Maximum Age: 1d0h0m0s
Maximum Message Size: unlimited
Maximum Consumers: unlimited
State:
Messages: 0
Bytes: 0 B
FirstSeq: 0
LastSeq: 0
Active Consumers: 0
Here be sure to set Replicas to how many Choria Brokers you have in your cluster should you require high availability of this data.
Note we set the subjects that the stream will ingest to choria.stream.input.registration.> this means all subjects below that path, each nodes data will go into a unique subject.
The Data Adapter again goes into broker.conf:
# /etc/choria/broker.conf
plugin.choria.adapters = inventory
plugin.choria.adapter.inventory.type = jetstream
plugin.choria.adapter.inventory.stream.topic = choria.stream.input.registration.%s
plugin.choria.adapter.inventory.ingest.topic = choria.broadcast.agent.registration
plugin.choria.adapter.inventory.ingest.protocol = request
Here we ingest data from choria.broadcast.agent.registration that will be in request format and place it into choria.stream.input.registration.%s where the %s gets replaced with the sender identity.
Fleet node configuration
We now instruct every node in our fleet to send it’s data found about itself in /etc/choria/node-metadata.json to the network where the Data Adapters will receive, validate and transform it into registration data.
registration = inventory_content
registration_splay = 120
registerinterval = 300
plugin.yaml = /etc/choria/node-metadata.json
plugin.choria.registration.inventory_content.target = choria.broadcast.agent.registration
plugin.choria.registration.inventory_content.compression = true
To avoid huge DoS when large fleets start we introduce a 2 minute splay - each node will sleep a random period up to 2 minutes before starting their registration publishes. We publish this data every 5 minutes and compress it.
Published data will include lists of agents, facts, classes, node statistics and more, see registration.InventoryData.
Target Stream
We should set up a Target in another NATS Cluster. The process is similar to the choria broker s add command above, but you can adjust retention to your liking, a day might be too short for example.
Advisories
We’ll capture advisories and replicate those as well. Add streams as below:
$ choria broker stream add CHORIA_REGISTRATION_ADVISORIES
? Subjects to consume choria.stream.input.registration_advisories
? Storage backend file
? Retention Policy Limits
? Discard Policy Old
? Stream Messages Limit -1
? Per Subject Messages Limit -1
? Stream size limit -1
? Maximum message age limit 1w
? Maximum individual message size -1
? Duplicate tracking time window 2m0s
? Allow message Roll-ups No
? Allow message deletion Yes
? Allow purging subjects or the entire stream Yes
? Replicas 1
Duplicate this stream in your target as well.
Stream Replicator
Finally we are ready to set up the replication strategy.
Given that nodes publish their data every 300 seconds, we’ll set it to send timeout advisories after 11 minutes, we’ll sample hourly data and publish advisories. To allow for late generation of the node-metadata.json file, we trigger on a 1024 byte payload change as well.
name: US-EAST
monitor_port: 9100
loglevel: info
state_store: /var/lib/stream-replicator
logfile: /var/log/stream-replicator.log
streams:
- stream: CHORIA_REGISTRATION
source_url: nats://choria.us-east.example.net:4222
target_url: nats://nats.central.example.net:4222
inspect_field: sender
inspect_duration: 1h
warn_duration: 11m
size_trigger: 1024
tls:
ca: /path/to/ca.pem
key: /path/to/key.pem
cert: /path/to/cert.pem
advisory:
subject: choria.stream.input.registration_advisories
reliable: true
- stream: CHORIA_REGISTRATION_ADVISORIES
source_url: nats://choria.us-east.example.net:4222
target_url: nats://nats.central.example.net:4222
tls:
ca: /path/to/ca.pem
key: /path/to/key.pem
cert: /path/to/cert.pem
I am not going too deep into the tls settings, choria enroll --certname stream.replicator or similar can do the Choria side, you might need target_tls for the other side.
We copy both the CHORIA_REGISTRATION and CHORIA_REGISTRATION_ADVISORIES streams to central, the CHORIA_REGISTRATION_ADVISORIES is not sampled in any way.
When you run the replicator data should start appearing centrally as well as advisories about node health.